7. Reinforcement learning for Control 🐶#
![]()
Attention
In this tutorial we are going to use the same CSTR example as in tutorial notebook 6. Therefore, it is a great idea to first look at tutorial 6 to have the complete context.
Goals of this exercise 🌟#
Perform reactor control using reinforcement learning
Revise the concept of transfer learning
Revise the concept of policy gradients
A quick reminder ✅#
Reinforcement Learning (RL) is an area of machine learning concerned with how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward.
RL algorithms are particularly well suited to address sequential decision making problems under uncertainty, for example, they are generally applied to solve problems in a Markov decision process (MDP) setting. A control problem (just like reactor control) is a sequential decision making problem under uncertainty, where at every time-step the controller (agent in the RL context) must take an optimal (control) action, and it is hindered by process disturbances (uncertainty). There are many types of reinforcement leanring algorithms, in this notebook tutorial we will focus on policy optimization algorithms.
We can define an RL agent as a controller that given a state \({\bf x}\) outputs the optimal action \({\bf u}\)
If the controller \(\pi(\cdot)\) is parametrized, say by neural network weights \(\boldsymbol{\theta}\), we can write
where \({\bf \theta}\) are parameters determined a priori. We could define the PID controller in this same fashion:
In many cases, to fullfil the exploration - exploitation dilemma or in games, stochastic policies are used, which instead of outputting a single action \({\bf u}\), output a distributions over actions \(p({\bf x};\boldsymbol{\theta})\).
In practice, it is common to have a neural network output the moments (mean and variance), and to then draw an action from the distribution parametrized by this mean and variance
You can find a Taxonomy of RL Algorithms below.

Fig. 8 A broad classification of reinforcement learning algorithms. source#
import torch
import torch.nn.functional as Ffunctional
import copy
import numpy as np
from scipy.integrate import odeint
import matplotlib.pyplot as plt
from pylab import grid
import time
The code below corresponds to the CSTR model and parameters of tutorial 6.
#@title CSTR code from tutorial 6
eps = np.finfo(float).eps
###############
# CSTR model #
###############
# Taken from http://apmonitor.com/do/index.php/Main/NonlinearControl
def cstr(x,t,u):
# == Inputs == #
Tc = u # Temperature of cooling jacket (K)
# == States == #
Ca = x[0] # Concentration of A in CSTR (mol/m^3)
T = x[1] # Temperature in CSTR (K)
# == Process parameters == #
Tf = 350 # Feed temperature (K)
q = 100 # Volumetric Flowrate (m^3/sec)
Caf = 1 # Feed Concentration (mol/m^3)
V = 100 # Volume of CSTR (m^3)
rho = 1000 # Density of A-B Mixture (kg/m^3)
Cp = 0.239 # Heat capacity of A-B Mixture (J/kg-K)
mdelH = 5e4 # Heat of reaction for A->B (J/mol)
EoverR = 8750 # E -Activation energy (J/mol), R -Constant = 8.31451 J/mol-K
k0 = 7.2e10 # Pre-exponential factor (1/sec)
UA = 5e4 # U -Heat Transfer Coefficient (W/m^2-K) A -Area - (m^2)
# == Equations == #
rA = k0*np.exp(-EoverR/T)*Ca # reaction rate
dCadt = q/V*(Caf - Ca) - rA # Calculate concentration derivative
dTdt = q/V*(Tf - T) \
+ mdelH/(rho*Cp)*rA \
+ UA/V/rho/Cp*(Tc-T) # Calculate temperature derivative
# == Return xdot == #
xdot = np.zeros(2)
xdot[0] = dCadt
xdot[1] = dTdt
return xdot
data_res = {}
# Initial conditions for the states
x0 = np.zeros(2)
x0[0] = 0.87725294608097
x0[1] = 324.475443431599
data_res['x0'] = x0
# Time interval (min)
n = 101 # number of intervals
tp = 25 # process time (min)
t = np.linspace(0,tp,n)
data_res['t'] = t
data_res['n'] = n
# Store results for plotting
Ca = np.zeros(len(t)); Ca[0] = x0[0]
T = np.zeros(len(t)); T[0] = x0[1]
Tc = np.zeros(len(t)-1);
data_res['Ca_dat'] = copy.deepcopy(Ca)
data_res['T_dat'] = copy.deepcopy(T)
data_res['Tc_dat'] = copy.deepcopy(Tc)
# noise level
noise = 0.1
data_res['noise'] = noise
# control upper and lower bounds
data_res['Tc_ub'] = 305
data_res['Tc_lb'] = 295
Tc_ub = data_res['Tc_ub']
Tc_lb = data_res['Tc_lb']
# desired setpoints
n_1 = int(n/2)
n_2 = n - n_1
Ca_des = [0.8 for i in range(n_1)] + [0.9 for i in range(n_2)]
T_des = [330 for i in range(n_1)] + [320 for i in range(n_2)]
data_res['Ca_des'] = Ca_des
data_res['T_des'] = T_des
##################
# PID controller #
##################
def PID(Ks, x, x_setpoint, e_history):
Ks = np.array(Ks)
Ks = Ks.reshape(7, order='C')
# K gains
KpCa = Ks[0]; KiCa = Ks[1]; KdCa = Ks[2]
KpT = Ks[3]; KiT = Ks[4]; KdT = Ks[5];
Kb = Ks[6]
# setpoint error
e = x_setpoint - x
# control action
u = KpCa*e[0] + KiCa*sum(e_history[:,0]) + KdCa*(e[0]-e_history[-1,0])
u += KpT *e[1] + KiT *sum(e_history[:,1]) + KdT *(e[1]-e_history[-1,1])
u += Kb
u = min(max(u,data_res['Tc_lb']),data_res['Tc_ub'])
return u
#@title Ploting routines
####################################
# plot control actions performance #
####################################
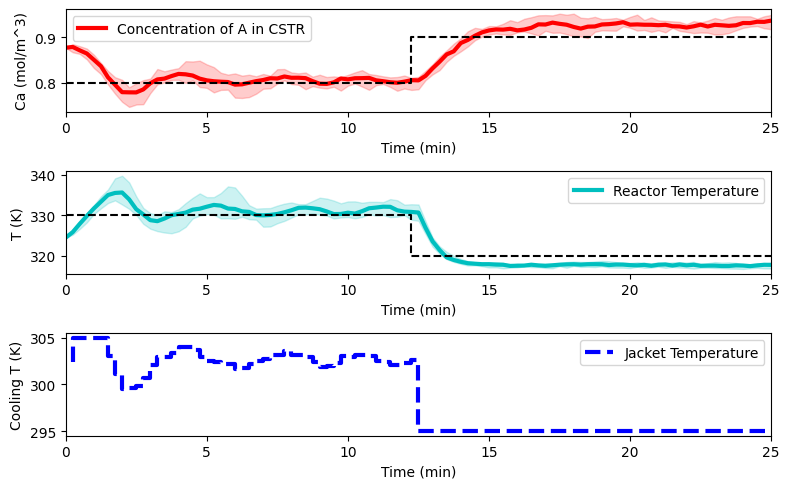
def plot_simulation(Ca_dat, T_dat, Tc_dat, data_simulation):
Ca_des = data_simulation['Ca_des']
T_des = data_simulation['T_des']
plt.figure(figsize=(8, 5))
plt.subplot(3,1,1)
plt.plot(t, np.median(Ca_dat,axis=1), 'r-', lw=3)
plt.gca().fill_between(t, np.min(Ca_dat,axis=1), np.max(Ca_dat,axis=1),
color='r', alpha=0.2)
plt.step(t, Ca_des, '--', lw=1.5, color='black')
plt.ylabel('Ca (mol/m^3)')
plt.xlabel('Time (min)')
plt.legend(['Concentration of A in CSTR'],loc='best')
plt.xlim(min(t), max(t))
plt.subplot(3,1,2)
plt.plot(t, np.median(T_dat,axis=1), 'c-', lw=3)
plt.gca().fill_between(t, np.min(T_dat,axis=1), np.max(T_dat,axis=1),
color='c', alpha=0.2)
plt.step(t, T_des, '--', lw=1.5, color='black')
plt.ylabel('T (K)')
plt.xlabel('Time (min)')
plt.legend(['Reactor Temperature'],loc='best')
plt.xlim(min(t), max(t))
plt.subplot(3,1,3)
plt.step(t[1:], np.median(Tc_dat,axis=1), 'b--', lw=3)
plt.ylabel('Cooling T (K)')
plt.xlabel('Time (min)')
plt.legend(['Jacket Temperature'],loc='best')
plt.xlim(min(t), max(t))
plt.tight_layout()
plt.show()
##################
# Training plots #
##################
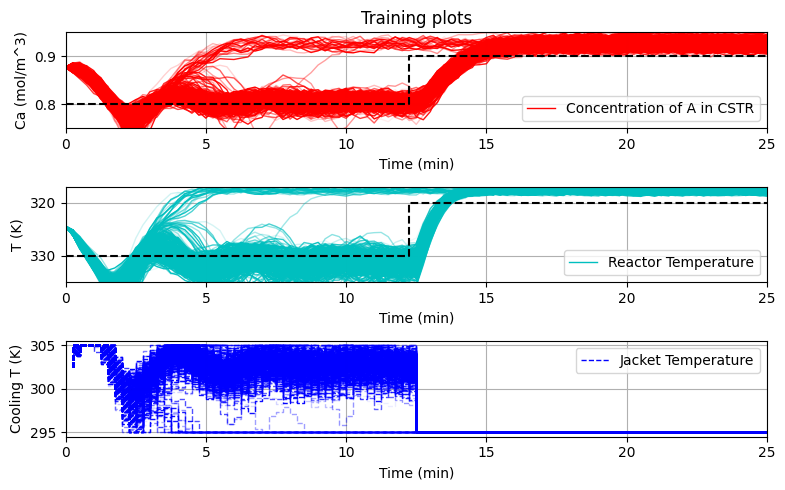
def plot_training(data_simulation, repetitions):
t = data_simulation['t']
Ca_train = np.array(data_simulation['Ca_train'])
T_train = np.array(data_simulation['T_train'])
Tc_train = np.array(data_simulation['Tc_train'])
Ca_des = data_simulation['Ca_des']
T_des = data_simulation['T_des']
c_ = [(repetitions - float(i))/repetitions for i in range(repetitions)]
plt.figure(figsize=(8, 5))
plt.subplot(3,1,1)
for run_i in range(repetitions):
plt.plot(t, Ca_train[run_i,:], 'r-', lw=1, alpha=c_[run_i])
plt.step(t, Ca_des, '--', lw=1.5, color='black')
plt.ylabel('Ca (mol/m^3)')
plt.xlabel('Time (min)')
plt.legend(['Concentration of A in CSTR'],loc='best')
plt.title('Training plots')
plt.ylim([.75, .95])
plt.xlim(min(t), max(t))
grid(True)
plt.subplot(3,1,2)
for run_i in range(repetitions):
plt.plot(t, T_train[run_i,:], 'c-', lw=1, alpha=c_[run_i])
plt.step(t, T_des, '--', lw=1.5, color='black')
plt.ylabel('T (K)')
plt.xlabel('Time (min)')
plt.legend(['Reactor Temperature'],loc='best')
plt.ylim([335, 317])
plt.xlim(min(t), max(t))
grid(True)
plt.subplot(3,1,3)
for run_i in range(repetitions):
plt.step(t[1:], Tc_train[run_i,:], 'b--', lw=1, alpha=c_[run_i])
plt.ylabel('Cooling T (K)')
plt.xlabel('Time (min)')
plt.legend(['Jacket Temperature'],loc='best')
plt.xlim(min(t), max(t))
grid(True)
plt.tight_layout()
plt.show()
#####################
# Convergence plots #
#####################
def plot_convergence(Xdata, best_Y, Objfunc=None):
'''
Plots to evaluate the convergence of standard Bayesian optimization algorithms
'''
## if f values are not given
f_best = 1e8
if best_Y==None:
best_Y = []
for i_point in range(Xdata.shape[0]):
f_point = Objfunc(Xdata[i_point,:], collect_training_data=False)
if f_point < f_best:
f_best = f_point
best_Y.append(f_best)
best_Y = np.array(best_Y)
n = Xdata.shape[0]
aux = (Xdata[1:n,:]-Xdata[0:n-1,:])**2
distances = np.sqrt(aux.sum(axis=1))
## Distances between consecutive x's
plt.figure(figsize=(9,3))
plt.subplot(1, 2, 1)
plt.plot(list(range(n-1)), distances, '-ro')
plt.xlabel('Iteration')
plt.ylabel('d(x[n], x[n-1])')
plt.title('Distance between consecutive x\'s')
plt.xlim(0, n)
grid(True)
# Best objective value found over iterations
plt.subplot(1, 2, 2)
plt.plot(list(range(n)), best_Y,'-o')
plt.title('Value of the best selected sample')
plt.xlabel('Iteration')
plt.ylabel('Best y')
grid(True)
plt.xlim(0, n)
plt.tight_layout()
plt.show()
Stochastic Policy Search 🎲#
Policy network#
In the same way as we used data-driven optimization to tune the gains \(K_P,K_I,K_D\) in the PID controllers (cf. tutorial notebook 6), we can use the same approach to tune (or train) the parameters (or weights) \(\boldsymbol{\theta}\) of a neural network.
There is research that suggest that evolutionary (or stochastic search in general) algorithms can be as good (or better in some contexts) than traditional techniques, for more details see Evolution Strategies as a Scalable Alternative to Reinforcement Learning, the paper can be found here.
The difference here, with respect to the controller tuning that we perform on tutorial notebook 6 is that the neural networks have many parameters and the number of iterations needed are relatively high, and therefore, model/surrogate-based data-driven optimization methods do not scale as well and might not be the best choice. Therefore, stochastic search optimization methods (e.g. genetic algorithms, particle swarm optimization) can be a good alternative. You can check some pedagogical implementations here.
In the following section we build a relatively simple neural network controller in PyTorch
and hard code a simple stochastic search algorithm (it is a combination of random search and local random search) to manipulate the weights \(\boldsymbol{\theta}\), evaluate the performance of the current weight values, and iterate.
Neural Network Controller Training Algorithm
Initialization
Collect \(d\) initial datapoints \(\mathcal{D}=\{(\hat{f}^{(j)}=\sum_{k=0}^{k=T_f} (e(k))^2,~ \boldsymbol{\theta}^{(j)}) \}_{j=0}^{j=d}\) by simulating \(x(k+1) = f(x(\cdot),u(\cdot))\) for different values of \(\boldsymbol{\theta}^{(j)}\), set a small radious of search \(r\)
Main loop
Repeat
\(~~~~~~\) Choose best current known parameter value \(\boldsymbol{\theta}^*\).
\(~~~~~~\) Sample \(n_s\) values around \(\boldsymbol{\theta}^*\), that are at most some distance \(r\), \(\bar{\boldsymbol{\theta}}^{(0)},...,\bar{\boldsymbol{\theta}}^{(n_s)}\)
\(~~~~~~\) Simulate new values \( x(k+1) = f(x(k),u(\bar{\boldsymbol{\theta}}^{(i)};x(k))), ~ k=0,...,T_f-1, i=0,...,n_s \)
\(~~~~~~\) Compute \(\hat{f}^{(i)}=\sum_{k=0}^{k=T_f} (e(k))^2, i=0,...,n_s\).
\(~~~~~~\) if \(\bar{\boldsymbol{\theta}}^{\text{best}}\) is better than \(\boldsymbol{\theta}^*\), then \( \boldsymbol{\theta}^* \leftarrow \bar{\boldsymbol{\theta}}^{\text{best}}\), else \( r \leftarrow r\gamma\), where \( 0 < \gamma <1 \)
until stopping criterion is met.
Remarks:
The initial collection of \(d\) points is generally done by some space filling (e.g. Latin Hypercube, Sobol Sequence) procedure.
First, let’s create a neural network in PyTorch that has two hidden layers, one being double the size of the input layer and the other double the size of the output layer. We will use the activation functions LeakyReLU and ReLU6. If you want a more gentle introduction to neural nets in Pytorch, check the tutorial notebook 4.
##################
# Policy Network #
##################
class Net(torch.nn.Module):
# in current form this is a linear function (wouldn't expect great performance here)
def __init__(self, **kwargs):
super(Net, self).__init__()
self.dtype = torch.float
# Unpack the dictionary
self.args = kwargs
# Get info of machine
self.use_cuda = torch.cuda.is_available()
self.device = torch.device("cpu")
# Define ANN topology
self.input_size = self.args['input_size']
self.output_sz = self.args['output_size']
self.hs1 = self.input_size*2
self.hs2 = self.output_sz*2
# Define layers
self.hidden1 = torch.nn.Linear(self.input_size, self.hs1 )
self.hidden2 = torch.nn.Linear(self.hs1, self.hs2)
self.output = torch.nn.Linear(self.hs2, self.output_sz)
def forward(self, x):
#x = torch.tensor(x.view(1,1,-1)).float() # re-shape tensor
x = x.view(1, 1, -1).float()
y = Ffunctional.leaky_relu(self.hidden1(x), 0.1)
y = Ffunctional.leaky_relu(self.hidden2(y), 0.1)
y = Ffunctional.relu6(self.output(y)) # range (0,6)
return y
We normalize the inputs and states
# normalization for states and actions
data_res['x_norm'] = np.array([[.8, 315,0, 0],[.1, 10,.1, 20]]) # [mean],[range]
data_res['u_norm'] = np.array([[10/6],[295]]) # [range/6],[bias]
Now, let’s create the objective function for the policy network.
Tip
Notice the difference between this objective function and the objective function use in tutorial 6. We have included a conditional to switch between algorithms.
def J_PolicyCSTR(policy, data_res=data_res, policy_alg='PID',
collect_training_data=True, traj=False, episode=False):
# load data
Ca = copy.deepcopy(data_res['Ca_dat'])
T = copy.deepcopy(data_res['T_dat'])
Tc = copy.deepcopy(data_res['Tc_dat'])
t = copy.deepcopy(data_res['t'])
x0 = copy.deepcopy(data_res['x0'])
noise = data_res['noise']
# setpoints
Ca_des = data_res['Ca_des']; T_des = data_res['T_des']
# upper and lower bounds
Tc_ub = data_res['Tc_ub']; Tc_lb = data_res['Tc_lb']
# normalized states and actions
x_norm = data_res['x_norm']; u_norm = data_res['u_norm'];
# initiate
x = x0
e_history = []
# log probs
if policy_alg == 'PG_RL':
log_probs = [None for i in range(len(t)-1)]
# Simulate CSTR
for i in range(len(t)-1):
# delta t
ts = [t[i],t[i+1]]
# desired setpoint
x_sp = np.array([Ca_des[i],T_des[i]])
#### PID ####
if policy_alg == 'PID':
if i == 0:
Tc[i] = PID(policy, x, x_sp, np.array([[0,0]]))
else:
Tc[i] = PID(policy, x, x_sp, np.array(e_history))
# --------------> New compared to tutorial 6 <-------------------
#### Stochastic Policy Search ####
elif policy_alg == 'SPS_RL':
xk = np.hstack((x,x_sp-x))
# state preprocesing
xknorm = (xk-x_norm[0])/x_norm[1]
xknorm_torch = torch.tensor(xknorm)
# compute u_k from policy
mean_uk = policy(xknorm_torch).detach().numpy()
u_k = np.reshape(mean_uk, (1, 1))
u_k = u_k*u_norm[0] + u_norm[1]
u_k = u_k[0]
u_k = min(max(u_k, Tc_lb), Tc_ub)
Tc[i] = u_k[0]
#### Policy Gradients ####
# See next section for the explanation on Policy gradients!
elif policy_alg == 'PG_RL':
xk = np.hstack((x,x_sp-x))
# state preprocesing
xknorm = (xk-x_norm[0])/x_norm[1]
xknorm_torch = Tensor(xknorm)
# compute u_k distribution
m, s = policy(xknorm_torch)[0,0]
s = s + eps
mean_uk, std_uk = mean_std(m, s)
u_k, logprob_k, entropy_k = select_action(mean_uk, std_uk)
u_k = np.reshape(u_k.numpy(), (nu))
# hard bounds on inputs
u_k = min(max(u_k, Tc_lb), Tc_ub)
Tc[i] = u_k
log_probs[i] = logprob_k
# ----------------------------------------------------------------
# simulate system
y = odeint(cstr,x,ts,args=(Tc[i],))
# add process disturbance
s = np.random.uniform(low=-1, high=1, size=2)
Ca[i+1] = y[-1][0] + noise*s[0]*0.1
T[i+1] = y[-1][1] + noise*s[1]*5
# state update
x[0] = Ca[i+1]
x[1] = T[i+1]
# compute tracking error
e_history.append((x_sp-x))
# == objective == #
# tracking error
error = np.abs(np.array(e_history)[:,0])/0.2+np.abs(np.array(e_history)[:,1])/15
# penalize magnitud of control action
u_mag = np.abs(Tc[:]-Tc_lb)/10
u_mag = u_mag/10
# penalize change in control action
u_cha = np.abs(Tc[1:]-Tc[0:-1])/10
u_cha = u_cha/10
# collect data for plots
if collect_training_data:
data_res['Ca_train'].append(Ca)
data_res['T_train'].append(T)
data_res['Tc_train'].append(Tc)
data_res['err_train'].append(error)
data_res['u_mag_train'].append(u_mag)
data_res['u_cha_train'].append(u_cha)
# sums
error = np.sum(error)
u_mag = np.sum(u_mag)
u_cha = np.sum(u_cha)
if episode:
# See next section for the explanation on Policy gradients!
sum_logprob = sum(log_probs)
reward = -(error + u_mag + u_cha)
return reward, sum_logprob
if traj:
return Ca, T, Tc
else:
return error + u_mag + u_cha
As mentioned above, we are going to use a stochastic search algorithm that combines random search with local random search to optimize the policy network.
The code below has two main elements:
Random Search Step: During this step neural network weights are sampled uniformely (given some bounds). Each set of parameters is evaluated (a simulation is run), and the parameter set that performed best is passed to the next step.
An illustration of how Random Search would look in a 2-dimensional space is shown below

Fig. 9 An illustration of the random search algorithm. source#
{kind=link}
Local Search Step: This step starts from the best parameter values found by the Random Search Step. Subsequently it does a random search close by the best value found (hence termed stocastic local search). Additionally, if after some number of interations a better function value has not been found (also via simulating the system), the radius of search is reduced.
An illustration of how Local search would look in a 2-dimensional space is shown below
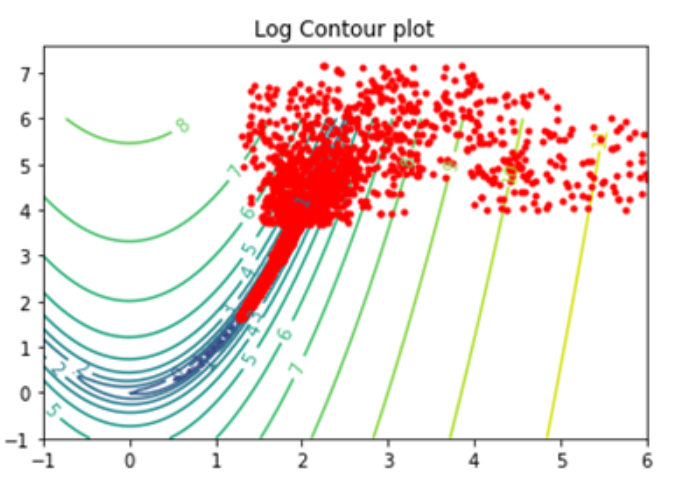
Fig. 10 An illustration of the local search algorithm.#
By combining a ‘global search’ strategy (Random search) and a ‘local search’ strategy (Local search) we balance exploration and exploitation which is a key concept in reinforcement learning.
#######################
# auxiliary functions #
#######################
def sample_uniform_params(params_prev, param_max, param_min):
params = {k: torch.rand(v.shape)* (param_max - param_min) + param_min \
for k, v in params_prev.items()}
return params
def sample_local_params(params_prev, param_max, param_min):
params = {k: torch.rand(v.shape)* (param_max - param_min) + param_min + v \
for k, v in params_prev.items()}
return params
#################################
# Generalized policy search
#################################
def Generalized_policy_search(shrink_ratio=0.5, radius=0.1, evals_shrink=1,
evals=12, ratio_ls_rs=0.3):
'''
Tailores to address function: J_BB_bioprocess(model, dt, x0, Umax, n_run, n_steps)
bounds: np.array([150,7])
'''
# adapt evaluations
evals_rs = round(evals*ratio_ls_rs)
evals_ls = evals - evals_rs
# problem initialisation
nu = 1
nx = 2
hyparams = {'input_size': nx+2, 'output_size': nu} # include setpoints +2
n_steps = data_res['n']
#######################
# policy initialization
#######################
policy_net = Net(**hyparams)
params = policy_net.state_dict()
param_max = 5# 1.5
param_min = -5#-1.5
# == initialise rewards == #
best_reward = 1e8
best_policy = copy.deepcopy(params)
###############
# Random search
###############
for policy_i in range(evals_rs):
# == Random Search in policy == #
# sample a random policy
NNparams_RS = sample_uniform_params(params, param_max, param_min)
# consrict policy to be evaluated
policy_net.load_state_dict(NNparams_RS)
# evaluate policy
reward = J_PolicyCSTR(policy_net, collect_training_data=True,
policy_alg='SPS_RL')
# benchmark reward ==> min "<"
if reward < best_reward:
best_reward = reward
best_policy = copy.deepcopy(NNparams_RS)
###############
# local search
###############
# define max radius
r0 = np.array([param_min, param_max])*radius
# initialization
iter_i = 0
fail_i = 0
while iter_i < evals_ls:
# shrink radius
if fail_i >= evals_shrink:
fail_i = 0
radius = radius*shrink_ratio
r0 = np.array([param_min, param_max])*radius
# new parameters
NNparams_LS = sample_local_params(best_policy, r0[1], r0[0])
# == bounds adjustment == #
# evaluate new agent
policy_net.load_state_dict(NNparams_LS)
reward = J_PolicyCSTR(policy_net, collect_training_data=True,
policy_alg='SPS_RL')
# choose the == Min == value
if reward < best_reward:
best_reward = reward
best_policy = copy.deepcopy(NNparams_LS)
fail_i = 0
else:
fail_i += 1
# iteration counter
iter_i += 1
print('final reward = ',best_reward)
print('radius = ',radius)
return best_policy, best_reward
# data for plots
data_res['Ca_train'] = []; data_res['T_train'] = []
data_res['Tc_train'] = []; data_res['err_train'] = []
data_res['u_mag_train'] = []; data_res['u_cha_train'] = []
# problem parameters
e_tot = 500
e_shr = e_tot/30
# Policy optimization
best_policy, best_reward = \
Generalized_policy_search(shrink_ratio=0.9, radius=0.1, evals_shrink=e_shr,
evals=e_tot, ratio_ls_rs=0.1)
final reward = 24.728396146934603
radius = 0.00886293811965251
plot_training(data_res, e_tot)
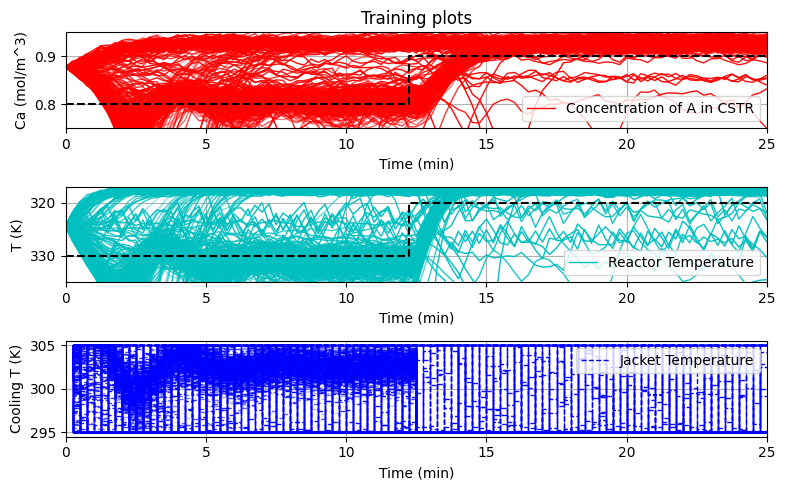
Notice that the ‘input size’ below has an extra +2. This is because we must pass the information to the policy network about the setpoint (given that our setpoint will change). Therefore, we give 2 extra inputs to our policy network, one for each setpoint.
nx = 2
nu = 1
hyparams = {'input_size': nx+2, 'output_size': nu} # include setpoints +2
policy_net_SPS_RL = Net(**hyparams, requires_grad=True, retain_graph=True)
policy_net_SPS_RL.load_state_dict(best_policy)
reps = 10
Ca_eval = np.zeros((data_res['Ca_dat'].shape[0], reps))
T_eval = np.zeros((data_res['T_dat'].shape[0], reps))
Tc_eval = np.zeros((data_res['Tc_dat'].shape[0], reps))
for r_i in range(reps):
Ca_eval[:,r_i], T_eval[:,r_i], Tc_eval[:,r_i] = J_PolicyCSTR(policy_net_SPS_RL,
policy_alg='SPS_RL',
collect_training_data=False,
traj=True)
# Plot the results
plot_simulation(Ca_eval, T_eval, Tc_eval, data_res)
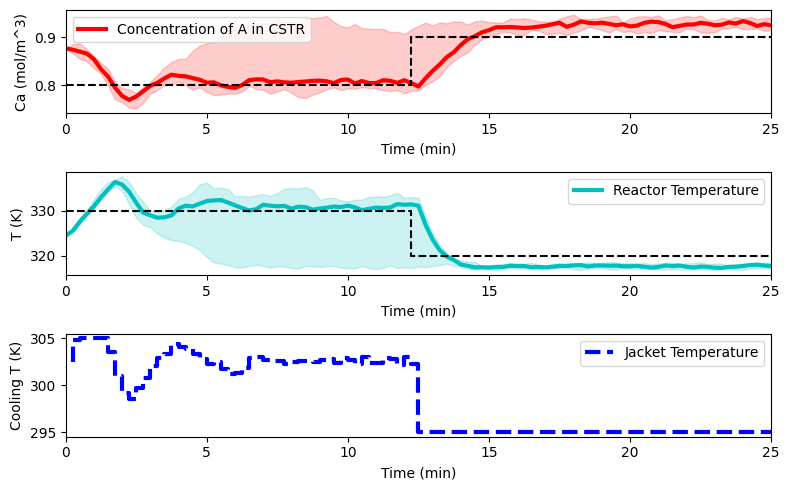
Remarks on stochastic policy search#
As it can be observed from the simple example above Stochastic local search methods work well in practice and are much easier to implement that other techniques (such as policy gradients). In general, as we move to large parameter spaces, for example neural networks with millions of parameters, their performance will deteriorate, and a policy gradient-like approach will be more desireable.
Policy Gradients 🗻#
Policy gradient methods rely on the Policy Gradient Theorem which allows to retrieve the gradient of the expected objective function with respect to policy parameters (neural network weights) \(\nabla_\theta \mathbb{E}_{\pi_\theta}[f(\pi_\theta)]\) through Monte Carlo runs. Given the availability of gradients, it is possible to follow a gradient-based optimization to optimize the policy, generally, Adam or Gradient Descent is used. More information can be found of Chapter 13 on Reinforcement Learning: An Introduction.
In this tutorial notebook we outline the simplest algorithm of this kind, Reinforce. For a more in dept introduction to the topic see Intro to Policy Optimization.
In the case of stochastic policies, the policy function returns the defining parameters of a probability distribution (such as the mean and variance) over possible actions, from which the actions are sampled: $\(\textbf{u} \sim \pi_\theta(\textbf{u} | \textbf{x}) = \pi(\textbf{u} | \textbf{x}, \theta) = p(\textbf{u} | \textbf{x}, \theta)\)$
Note*: this is the same as the stochastic policy introduced earlier, following the ‘probability notation’.
To learn the optimal policy, we seek to maximize our performance metric, and hence we can follow a gradient ascent strategy: $\(\theta_{m+1} = \theta_m + \alpha_m \nabla_\theta \mathbb{E}_{\pi_\theta}[f(\pi_\theta)] \)$
where \(m\) is the current iteration that the parameters are updated (epoch), \(\nabla_\theta \mathbb{E}_{\pi_\theta}[f(\pi_\theta)]\) is the expectation of \(f\) over \(\pi_\theta\) and \(\alpha_m\) is the step size (also termed learning rate in the RL community) for the \(m^{th}\) iteration.
Computing \( \nabla_\theta \hat{f}(\theta) = \nabla_\theta\mathbb{E}_{\pi_\theta}[J(\pi_\theta)]\) directly is difficult, therefore we use the Policy Gradient Theorem, which shows the following:
Notice from the first expression, that, \(p(\pi_\theta|\theta)~ f(\pi_\theta)\) is an objective function value multiplied by its probability density, therefore, integrating this over all possible values of \(\pi_\theta\) we obtain the expected value. From there, using simple algebra, logarithms and the chain rule, we arrive at the final equations, which shows an expected value, where, dropping the explicit distribution of \(\pi_\theta\), gives us an unbiased gradient estimator, our steepest ascent update now becomes:
Using the expression for \(p(\pi_\theta|\theta) = \hat{\mu}(\textbf{x}_0) \prod_{t=0}^{T-1} \left[\pi(\textbf{u}_t|\textbf{x}_t,\theta) p(\textbf{x}_{t+1}|\textbf{x}_t,\textbf{u}_t) \right]\) and taking its logarithm, we obtain:
Note that since \(p(\textbf{x}_{t+1}|\textbf{x}_t,\textbf{u}_t)\) and \(\hat{\mu}(\textbf{x}_0)\) are independent of \(\theta\) they disappear from the above expression. Then we can rewrite for a trajectory as:
The above expression does not require the knowledge of the dynamics of the physical system. Monte-Carlo method is utilized to approximate the expectation.
Reinforce algorithm
\({\bf Input:}\) Initialize policy parameter \(\theta = \theta_0\), with \(\theta_0\in\Theta_0\), learning rate \(\alpha\), set number of episodes \(K\) and number of epochs \(N\).
\({\bf Output:}\) policy \(\pi(\cdot | \cdot ,\theta)\) and \(\Theta\) \smallskip
\({\bf for}\) \(m = 1,\dots, N\) \({\bf do}\)
Collect \(\textbf{u}_t^k , \textbf{x}_t^k,f(\pi_\theta^k)\) for \(K\) trajectories of \(T\) time steps.
Estimate the gradient \( \hat{g}_m := \frac{1}{K} \sum_{k=1}^{K} \left[ f(\pi_\theta^k) \nabla_\theta \sum_{t=0}^{T-1} \text{log}\left( \pi(\textbf{u}_t^k|\hat{\textbf{x}}_t^k,\theta)\right)\right]\)
Update the policy using a policy gradient estimate \(\theta_{m+1} = \theta_m + \alpha_m \hat{g}_m\)
\(m:=m+1\)
\({\bf Remark}\): The above algorithm is the base version for many further developments that have been made since it was first proposed.
The steps of the algorithm are explained below:
\({\bf Initialization:}\) The policy network and its weights \(\theta\) are initialized along with the algorithm’s hyperparameters such as learning rate, number of episodes and number of epochs.
\({\bf Training ~~ loop:}\) The weights of the policy network are updated by a policy gradient scheme for a total of \(N\) epochs.
In \({\bf Step 1}\) \(K\) trajectories are computed, each trajectory consists of \(T\) time steps, and states and control actions are collected.
In \({\bf Step 2}\) the gradient of the objective function with respect to the weights for the policy network is computed.
In \({\bf Step 3}\) the weights of the policy network are updated by a gradient ascent scheme. Note that here we show a steepest ascent-like update, but other first order (i.e. Adam) or trust region methods can be used (i.e. PPO, TRPO).
In \({\bf Step 4}\), either the algorithm terminates or returns to Step 1.
import torch.nn as nn
import torch.optim as optim
from torch import Tensor
from torch.distributions import MultivariateNormal
In order to implement and apply the Reinforce algorithm, we are going to perform the following steps in the following subsections:
Create a policy network that uses transfer learning
Create an auxiliary function that selects control actions out of the distribution
Create an auxilary function that runs multiple episodes per epoch
Finally, put all the pieces together into a function that computes the Reinforce algorithm
Policy network#
In the next section of this tutorial notebook we show an implementation from scratch of a policy optimization algorithm using policy gradients.
Given that we have already optimized the policy via stochastic search in the previous section, we use those parameters as a starting point for policy gradients. This is a form of transfer learning, which refers to applying knowledge that was previously gained while solving one task to a related task.
Related to this transfer learning process, we will create a second neural network with the exact same configuration as before, but we will add an extra node to each output of the original neural network to account for the variance term. This is because previously our neural network policy had the structure:
and by a Stochastic search algorithm we manipulated the weights \(\boldsymbol{\theta}\) to optimize performance. In policy gradients we output a distribution, rathen than a single value, in this case we output the mean and the variance of a normal distribution (each output now has two values, the mean and the variance), and therefore we must add an extra node to each output such that we have:
#########################################
# Policy Network with transfer learning #
#########################################
class Net_TL(torch.nn.Module):
# in current form this is a linear function (wouldn't expect great performance here)
def __init__(self, **kwargs):
super(Net_TL, self).__init__()
self.dtype = torch.float
# Unpack the dictionary
self.args = kwargs
# Get info of machine
self.use_cuda = torch.cuda.is_available()
self.device = torch.device("cpu")
# Define ANN topology
self.input_size = self.args['input_size']
self.output_sz = self.args['output_size']
self.hs1 = self.input_size*2
self.hs2 = self.output_sz*2
# Define layers
self.hidden1 = torch.nn.Linear(self.input_size, self.hs1 )
self.hidden2 = torch.nn.Linear(self.hs1, self.hs2)
self.output = torch.nn.Linear(self.hs2, self.output_sz)
def forward(self, x):
#x = torch.tensor(x.view(1,1,-1)).float() # re-shape tensor
x = x.view(1, 1, -1).float()
y = Ffunctional.leaky_relu(self.hidden1(x), 0.1)
y = Ffunctional.leaky_relu(self.hidden2(y), 0.1)
y = Ffunctional.relu6(self.output(y)) # range (0,6)
return y
def increaseClassifier(self, m:torch.nn.Linear):
w = m.weight
b = m.bias
old_shape = m.weight.shape
m2 = nn.Linear( old_shape[1], old_shape[0] + 1)
m2.weight = nn.parameter.Parameter( torch.cat( (m.weight, m2.weight[0:1]) ),
requires_grad=True )
m2.bias = nn.parameter.Parameter( torch.cat( (m.bias, m2.bias[0:1]) ),
requires_grad=True)
return m2
def incrHere(self):
self.output = self.increaseClassifier(self.output)
Notice that just as before, we ad a +2 to the input, as thisrefers to the current set-point value.
nx = 2
nu = 1
hyparams = {'input_size': nx+2, 'output_size': nu} # include setpoints +2
policy_net_pg = Net_TL(**hyparams, requires_grad=True, retain_graph=True)
policy_net_pg.load_state_dict(best_policy) # Transfer learning
policy_net_pg.incrHere()
Control action selection#
################################
# action selection from Normal #
################################
def select_action(control_mean, control_sigma):
"""
Sample control actions from the distribution their distribution
input: Mean, Variance
Output: Controls, log_probability, entropy
"""
s_cov = control_sigma.diag()**2
dist = MultivariateNormal(control_mean, s_cov)
control_choice = dist.sample() # sample control from N(mu,std)
log_prob = dist.log_prob(control_choice) # compute log prob of this action (how likely or unlikely)
entropy = dist.entropy() # compute the entropy of the distribution N(mu, std)
return control_choice, log_prob, entropy
#########################
# un-normalizing action #
#########################
def mean_std(m, s, mean_range=[10], mean_lb=[295], std_range=[0.001]):
'''
Problem specific restrictions on predicted mean and standard deviation.
'''
mean = Tensor(mean_range) * m/6 + Tensor(mean_lb) # ReLU6
std = Tensor(std_range) * s/6
return mean, std
Multiple episodes - one epoc/training step#
################
# one epoc run #
################
def epoc_run(NNpolicy, episodes_n):
'''This function runs episodes_n episodes and collected the data. This data
is then used for one gradient descent step.
INPUTS
NNpolicy: the NN policy
episodes_n: number of episodes per epoc (gradient descent steps)
data_train: dictionary of data collected
OUTPUTS
data_train: collected data to be passed to the main training loop
'''
# run episodes
logprobs_list = [] # log probabilities is the policies itself p(a|s)
reward_list = [] # reward
for epi_i in range(episodes_n):
reward_, sum_logprob = J_PolicyCSTR(NNpolicy, policy_alg='PG_RL',
collect_training_data=True, episode=True)
logprobs_list.append(sum_logprob)
reward_list.append(reward_)
# compute mean and expectation of rewards
reward_m = np.mean(reward_list)
reward_std = np.std(reward_list)
# compute the baseline (reverse sum)
log_prob_R = 0.0
for epi_i in reversed(range(episodes_n)):
baselined_reward = (reward_list[epi_i] - reward_m) / (reward_std + eps)
log_prob_R = log_prob_R - logprobs_list[epi_i] * baselined_reward
# mean log probability
mean_logprob = log_prob_R/episodes_n
reward_std = reward_std
reward_m = reward_m
return mean_logprob, reward_std, reward_m
Reinforce algorithm#
Now, let’s create a function that put all pieces together and implements the Reinforce algorithm explained above
def Reinforce(policy, optimizer, n_epochs, n_episodes):
# lists for plots
rewards_m_record = []; rewards_std_record = []
for epoch_i in range(n_epochs):
# collect data
mean_logprob, reward_std, reward_m = epoc_run(policy, n_episodes)
# Expected log reward
E_log_R = mean_logprob
optimizer.zero_grad()
E_log_R.backward()
optimizer.step()
# save data for analysis
rewards_m_record.append(reward_m)
rewards_std_record.append(reward_std)
# schedule to reduce lr
scheduler.step(E_log_R)
if epoch_i%int(n_epochs/10)==0:
mean_r = reward_m
std_r = reward_std
print('epoch:', epoch_i)
print(f'mean reward: {mean_r:.3} +- {std_r:.2}')
return rewards_m_record, rewards_std_record, policy
Apply the Reinforce algorithm#
Now that we have the algorithm, let’s apply it to the problem.
Let’s choose some problem parameters and initialize storing lists
# problem parameters
lr = 0.0001
total_it = 2000
n_episodes = 50
n_epochs = int(total_it/n_episodes)
# data for plots
data_res['Ca_train'] = []; data_res['T_train'] = []
data_res['Tc_train'] = []; data_res['err_train'] = []
data_res['u_mag_train'] = []; data_res['u_cha_train'] = []
define the policy and the optimizer to be used
# define policy and optimizer
control_policy = policy_net_pg
optimizer_pol = optim.Adam(control_policy.parameters(), lr=lr)
define the learning rate scheduler
# Define Scheduler
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer_pol, factor=0.5, patience=10, verbose=True, min_lr=0.000001,
cooldown = 10)
and apply the algorithm
Note
Runing the algorithm will last for a few minutes
rewards_m_record, rewards_std_record, optimal_Reinforce = \
Reinforce(control_policy, optimizer_pol, n_epochs, n_episodes)
epoch: 0
mean reward: -32.8 +- 1.2e+01
epoch: 4
mean reward: -30.1 +- 6.5
epoch: 8
mean reward: -31.3 +- 8.8
epoch: 12
mean reward: -30.9 +- 8.6
Epoch 00017: reducing learning rate of group 0 to 5.0000e-05.
epoch: 16
mean reward: -30.4 +- 6.3
epoch: 20
mean reward: -29.2 +- 1.9
epoch: 24
mean reward: -30.3 +- 6.1
epoch: 28
mean reward: -29.7 +- 6.1
epoch: 32
mean reward: -31.9 +- 9.0
epoch: 36
mean reward: -32.0 +- 1.1e+01
Epoch 00038: reducing learning rate of group 0 to 2.5000e-05.
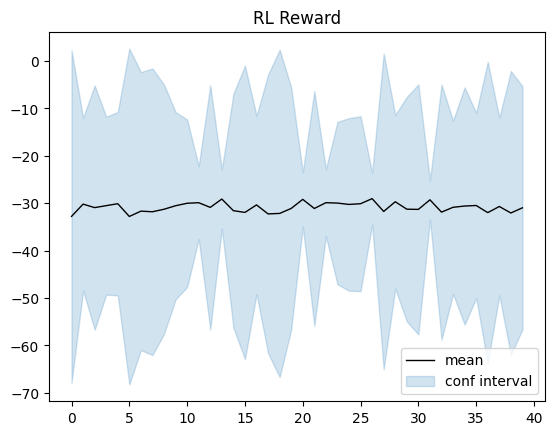
Let’s visualize now
# plot the samples of posteriors
plt.plot(rewards_m_record, 'black', linewidth=1)
# plot GP confidence intervals
iterations = [i for i in range(len(rewards_m_record))]
plt.gca().fill_between(iterations, np.array(rewards_m_record) - 3*np.array(rewards_std_record),
np.array(rewards_m_record) + 3*np.array(rewards_std_record),
color='C0', alpha=0.2)
plt.title('RL Reward')
plt.legend(('mean', 'conf interval'),
loc='lower right')
plt.show()
plot_training(data_res, e_tot)
reps = 10
Ca_eval = np.zeros((data_res['Ca_dat'].shape[0], reps))
T_eval = np.zeros((data_res['T_dat'].shape[0], reps))
Tc_eval = np.zeros((data_res['Tc_dat'].shape[0], reps))
for r_i in range(reps):
Ca_eval[:,r_i], T_eval[:,r_i], Tc_eval[:,r_i] = J_PolicyCSTR(policy_net_pg,
policy_alg='PG_RL',
collect_training_data=False,
traj=True)
# Plot the results
plot_simulation(Ca_eval, T_eval, Tc_eval, data_res)
Extra material on RL for ChemEng 🤓#
If you would like to read more about the use of reinforcement learning in chemical engineering systems:
Applications
Reinforcement learning offers potential for bringing significant improvements to industrial batch process control practice even in discontinous and nonlinear systems.
RL has also been used to address chemical production scheduling and multi-echelon supply chains
Other applications include PID tuning, real-time optimization, searching for optimal process routes, flowsheet generation, bioreactors and biotherapeutics, amongst many others.
Methodologies
Constraints to address plant-model mismatch, constrained Q-learning, safe reinforcement learning, satisfaction of constraints with high probability, and dynamic penalties for better convergence.
Process control, meta-reinforcement learning, general economic process control, amongst many many others.